Data Scientist是新兴热门行业,业界供不应求!
而且Data Scientist岗申请面非常广。
例如Investment Banking, Hedge Fund, Fintech, Credit Card, IT, Media, Healthcare, Pharmaceutical等各大行业全都招人。
简历做得好可以随便拿面试,未必非要Networking求人refer。
Data Scientist面试总结:12家公司面试机会
Summary: 我投了差不多600份申请,一共12家公司给我发了面试,6个On-Site,最后拿下了4个Offer。
Roughly Speaking: Submit 50 Applications - Get 1 Interview; Submit 100 Applications - Get 1 On-Site; Submit 150 Applications - Get 1 Offer
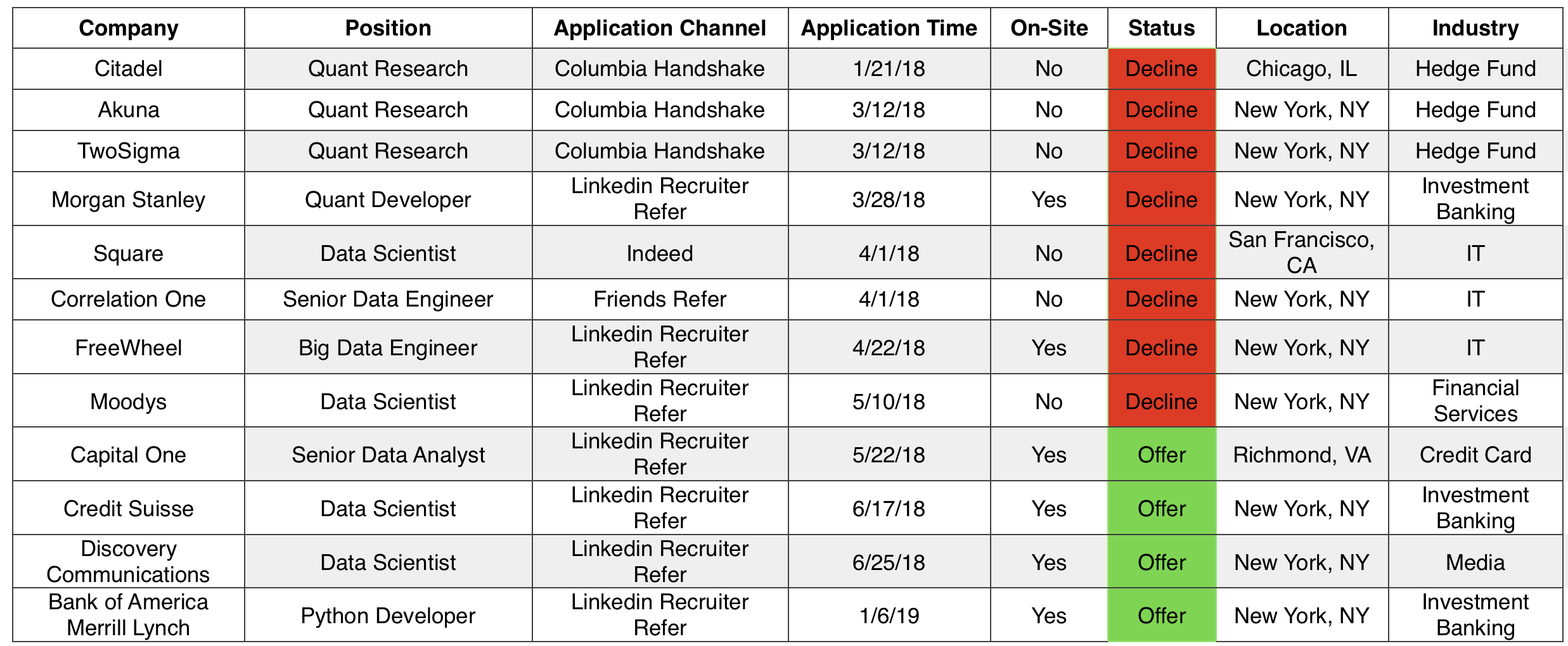
Industry8类: Hedge Fund, Investment Banking, IT, Fintech, Media, Credit Card, Financial Services, Education
可以粗略总结为:金融相关+IT相关的公司更喜欢给我发面试
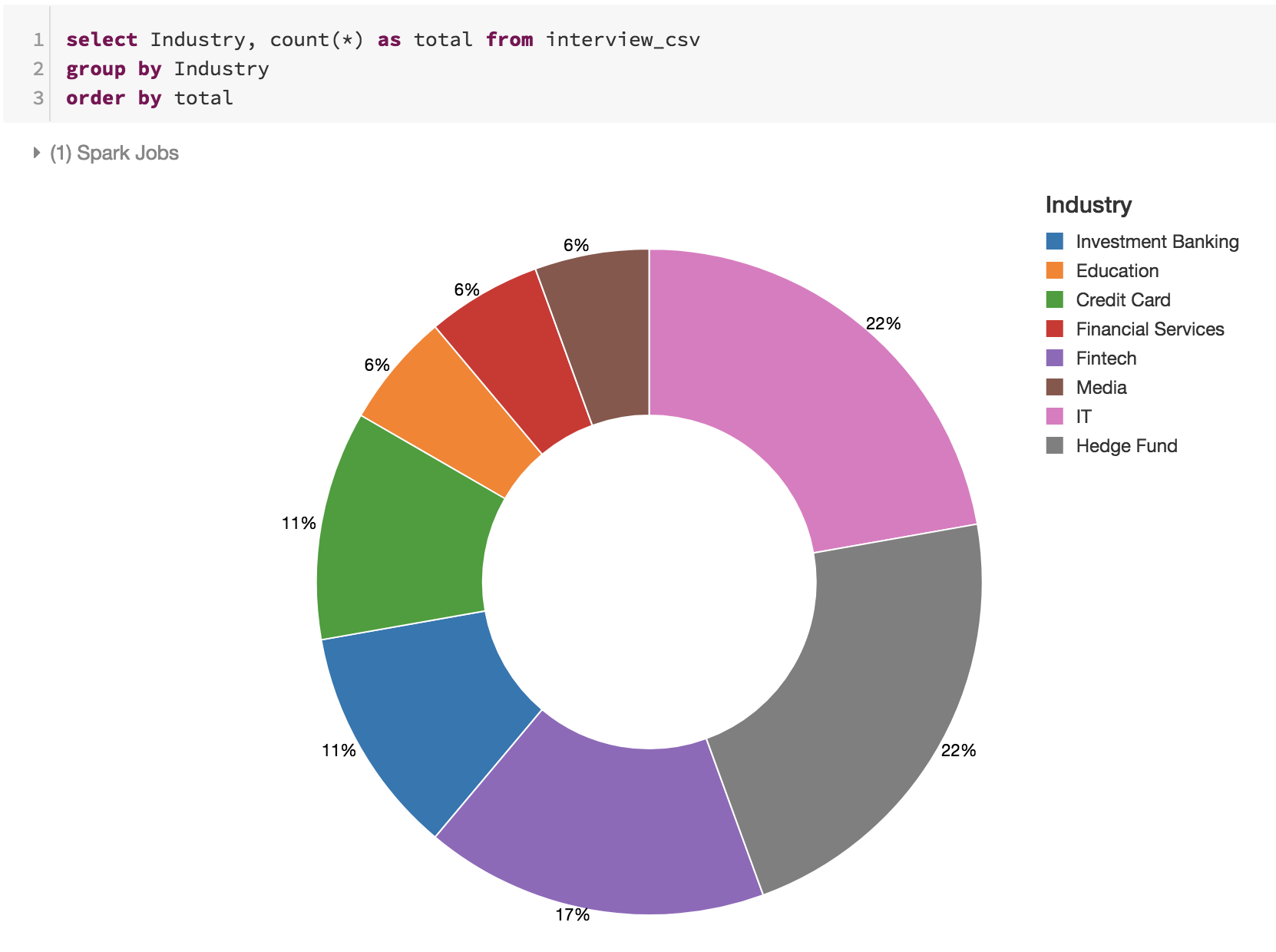
Position7种: Data Scientist, Quant Research, Senior Data Engineer, Big Data Engineer, Data Analyst II, Senior Business Analyst, Algo Trading
岗位:所有给面试的公司中,一半是Data Scientist岗,接下来是Quant Research岗占22%
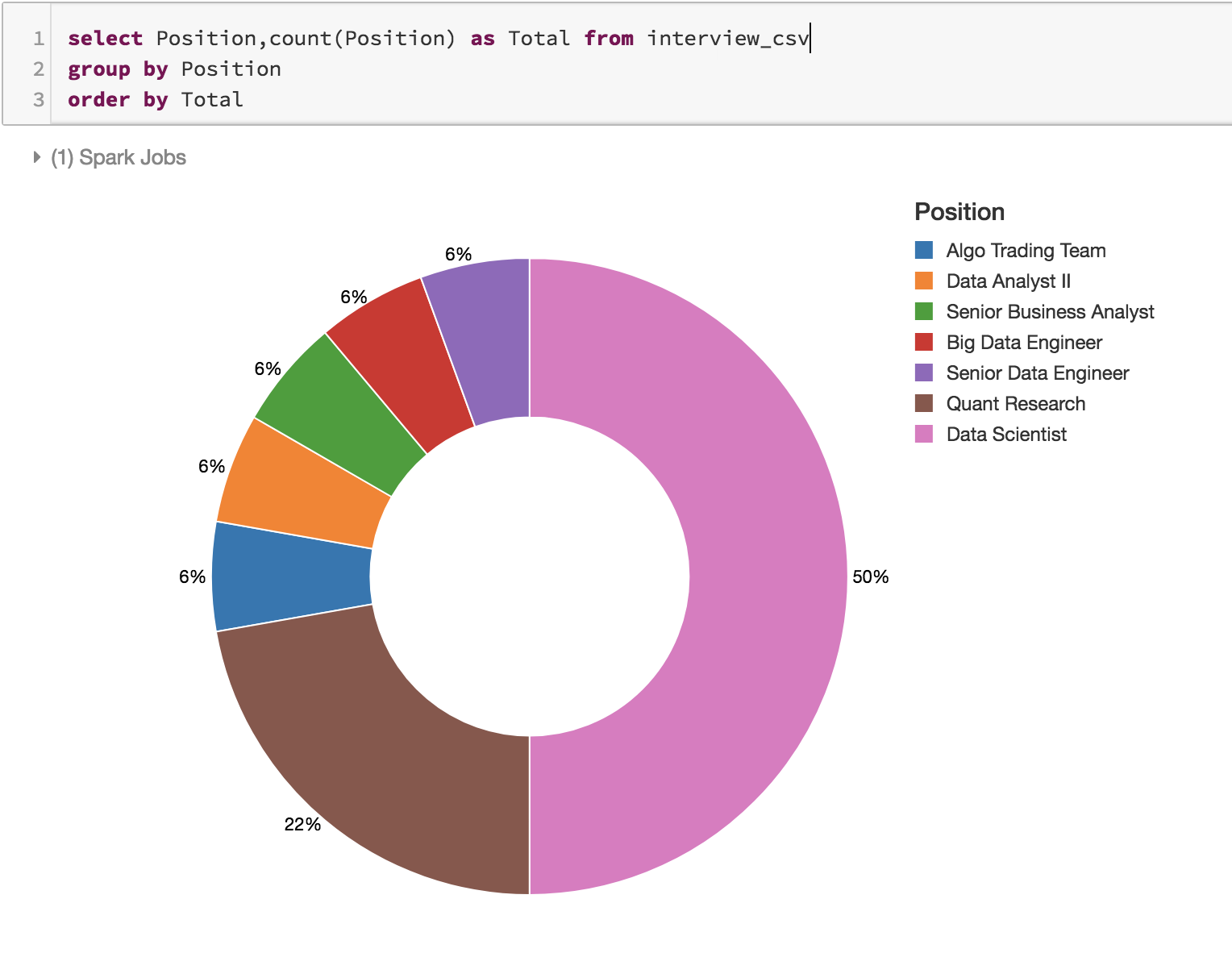
Channel8个: Linkedin, Linkedin Recruiter Refer, Indeed, Handshake, Monster,Professor Refer, Friends Refer, Recruiter Refer
申请媒介:18家公司中,15家公司要么是自己在网上投的简历,要么是我把简历挂在Linkedin上公司的Recruiter直接联系的我给我安排面试,只有3家公司是求人帮忙Refer的
总之,83%的面试都是靠我自己的简历拿到的!
简历小课堂1: Resume的筛选系统
你把简历提交了之后,首先第一关就是要过公司内部自己的简历筛选系统。
我之前一直在用的是TopResume的系统,完全是免费的,他们这个系统据说是模拟了很多公司的简历筛选系统,会给你提很多意见然后让你买他们家改简历的plan,我觉得没什么必要去专门花钱找人改简历,一份好的简历都是自己一点一点build起来的。
毕竟只有你自己才最了解自己,你可以把简历当成是自己职业形象的一个缩影,就跟自拍一样,我想大部分人都想要别人看到自己最好的一面,所以就要用各种美好的词汇和结构去装饰自己的经历。
当然,最终目标只有一个,就是拿到尽可能多的面试!
Topresume免费Evaluation: https://www.topresume.com/resume-review,或者去Glassdoor提交简历时会问你是否要一个TopResume的Free Review点Yes。
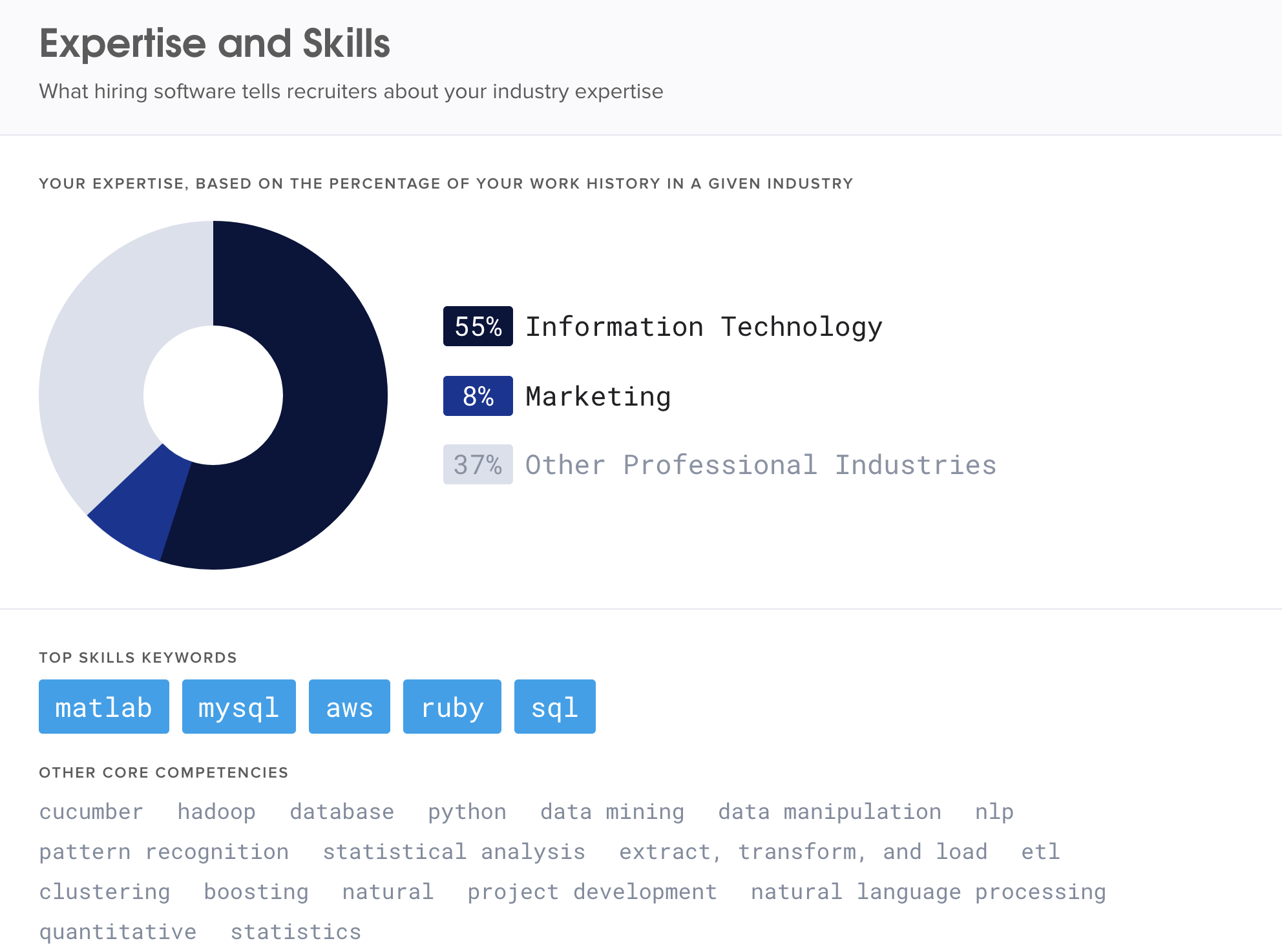
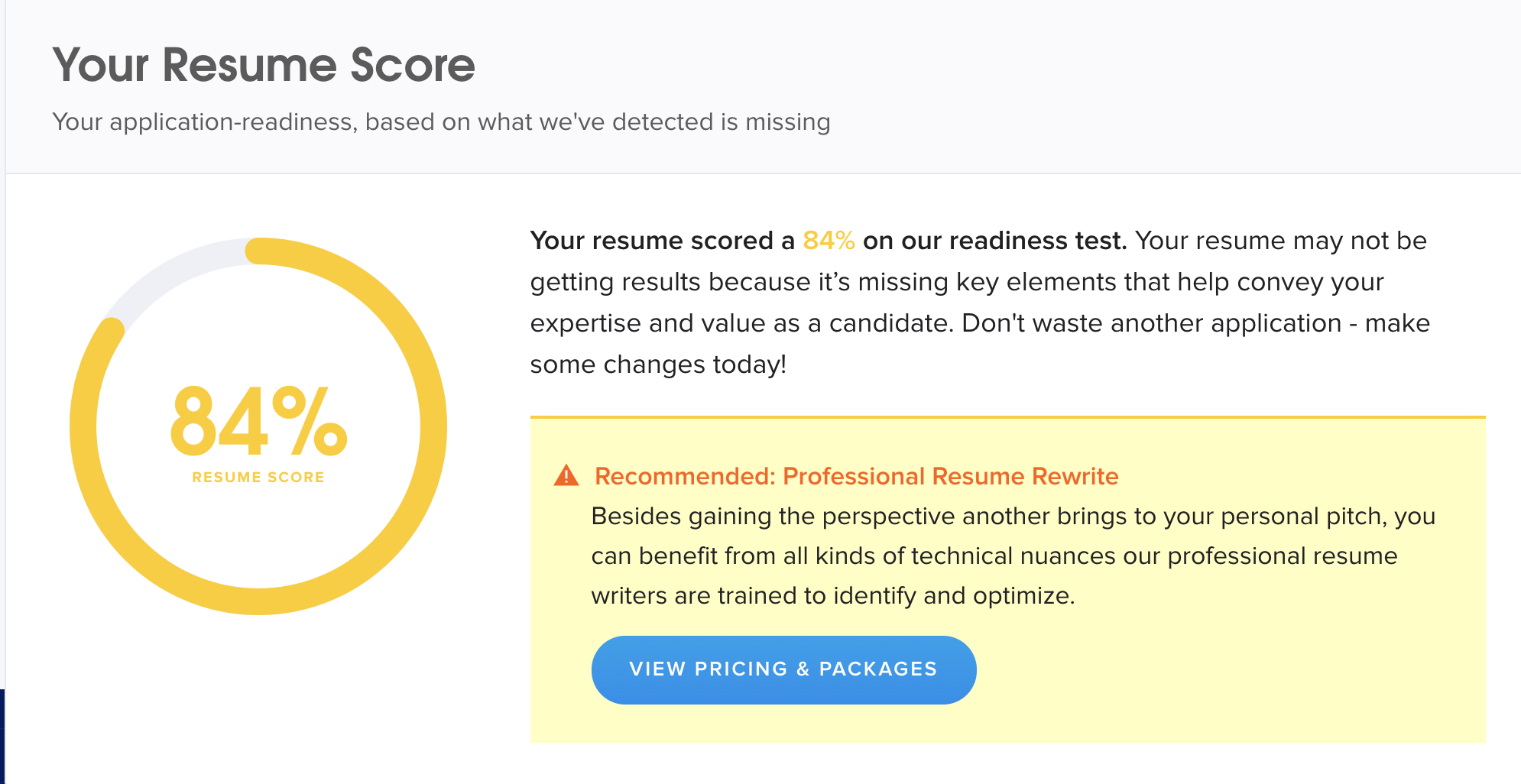
这样你可以对自己的简历有一个比较直观的印象,我认为比较有用的是Expertise and Skills这一项,会给出一个你总体经历主要集中在哪个Industry。
比如,你IT占据主导Industry,结果你非要去投Risk岗,这样你简历的匹配度就会非常的低,导致非常难拿面试!
简历小课堂2: Resume的匹配度
大多简历筛选系统都会给你一个百分比排名,我估计就是根据匹配度算出的。
打开Linkedin到Jobs一项每一个岗位Linkedin都会算出你的profile在所有申请者里面的排名。我的profile投几乎所有Data Scientist岗都是Top 10%。
(Linkedin需要买Premium才能看pofile分析)
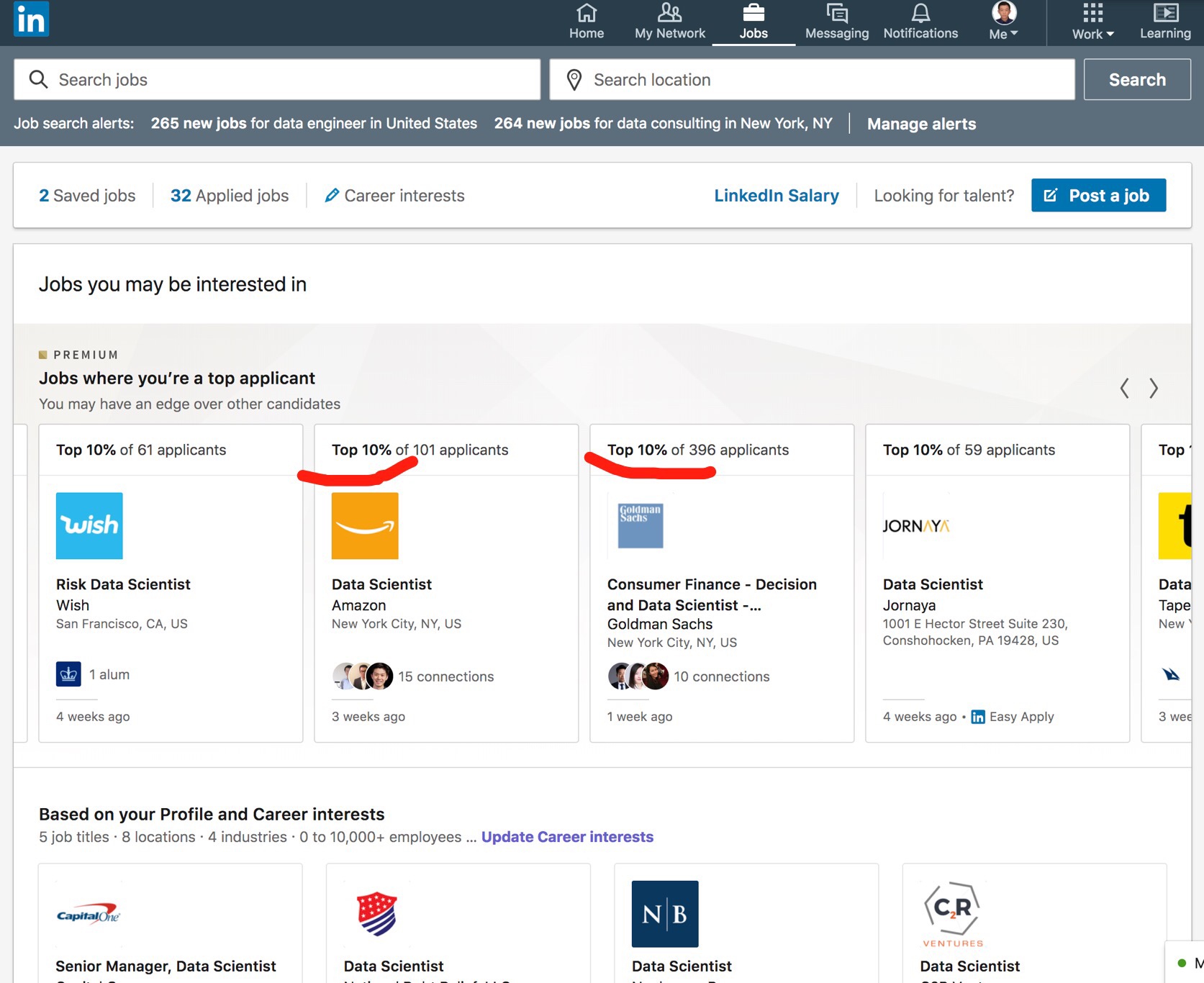
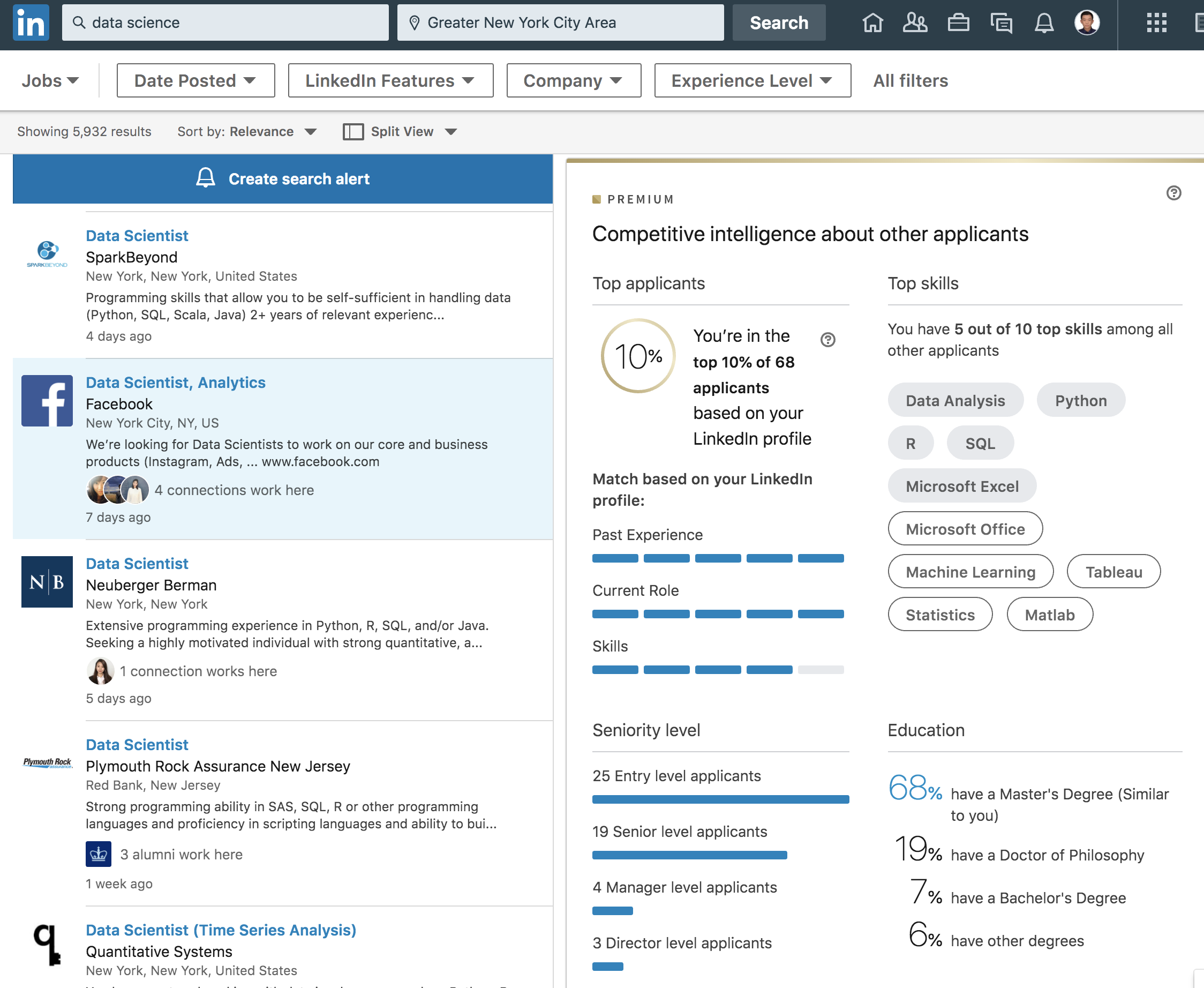
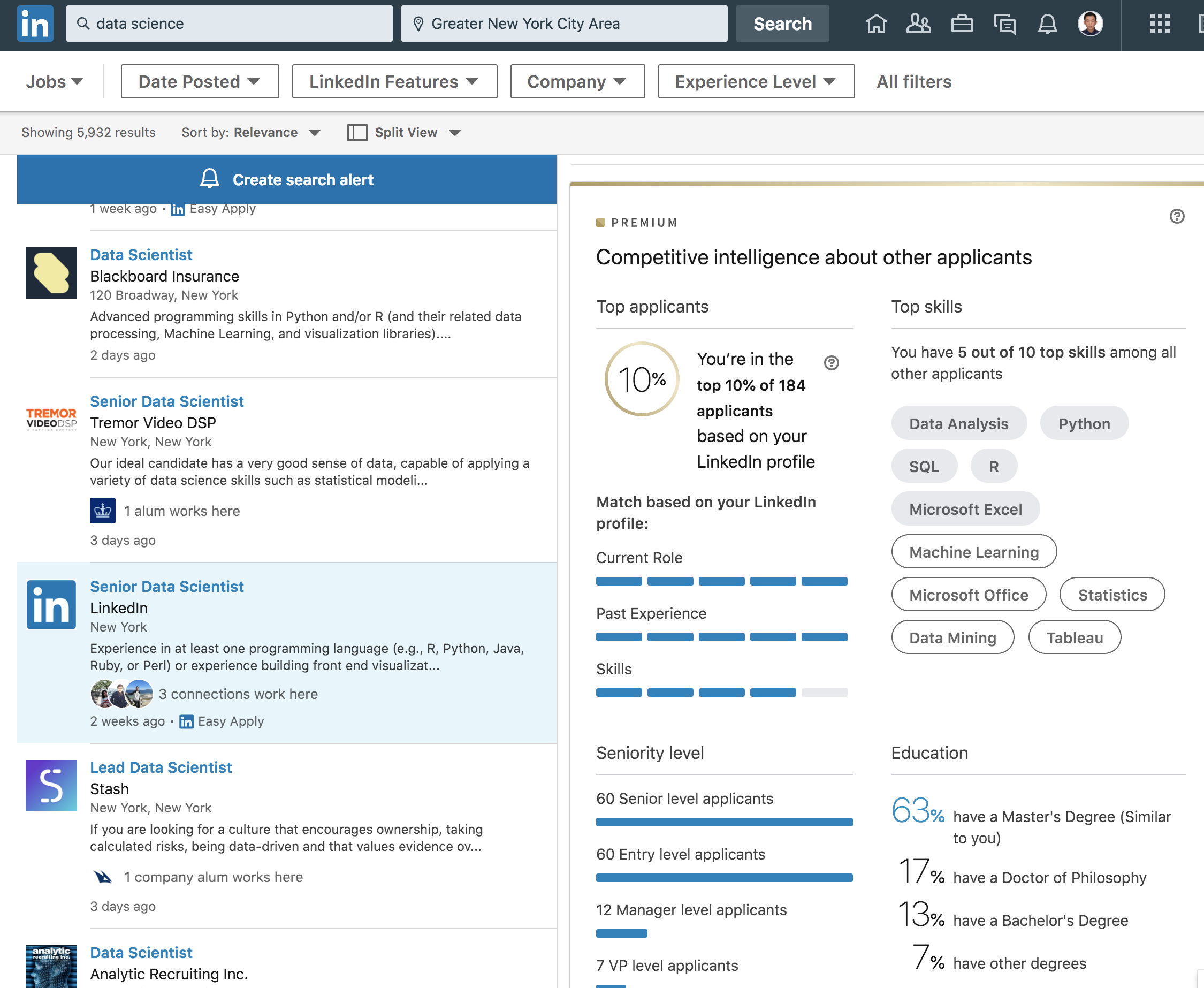
为了验证一下其他岗位,同样是德意志银行DS岗我排10%,Data Engineer岗我排25%,高盛的Python Developer我排25%,UBS的Data Analyst我排50%,摩根大通的Risk岗我排50%。
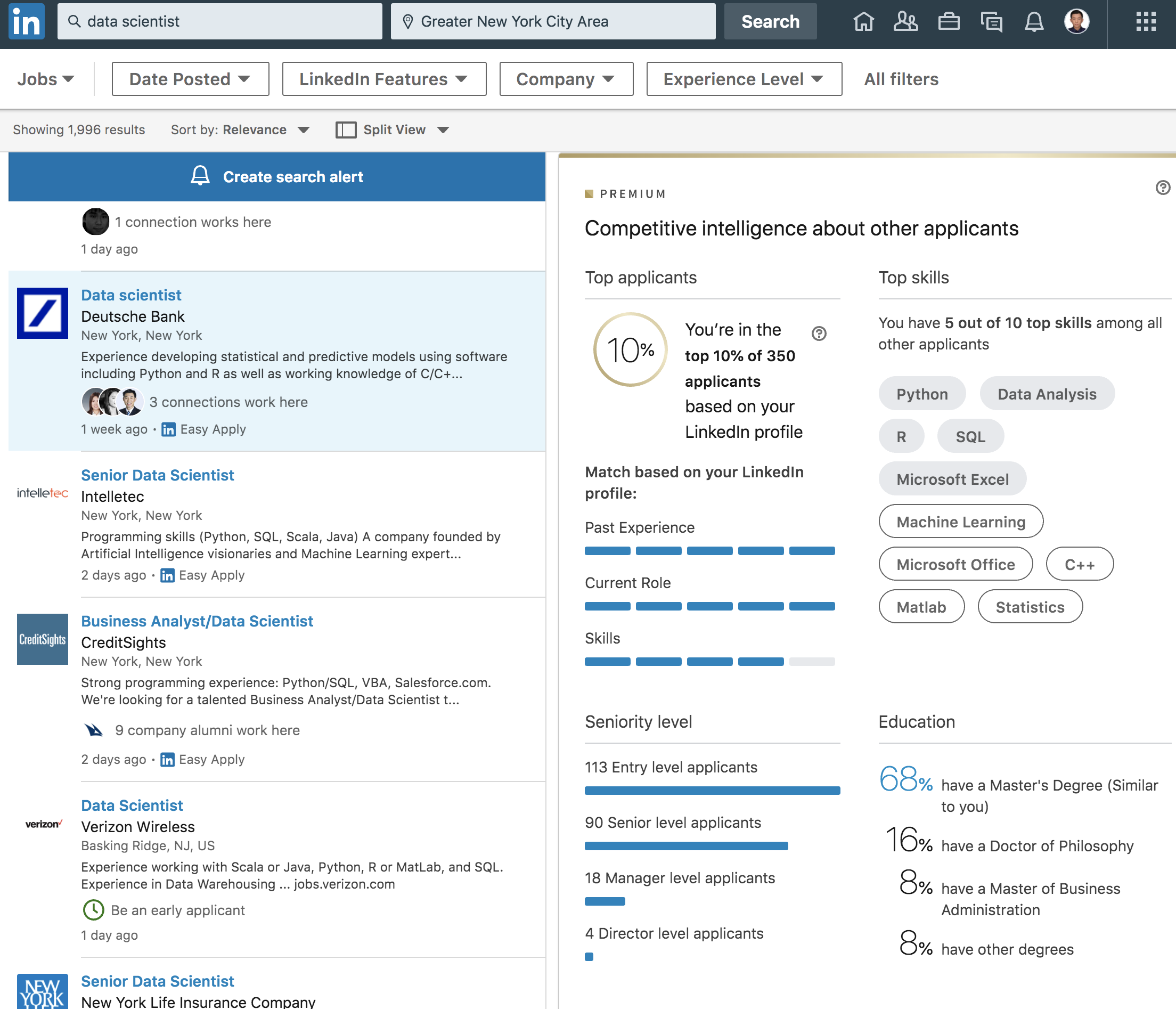
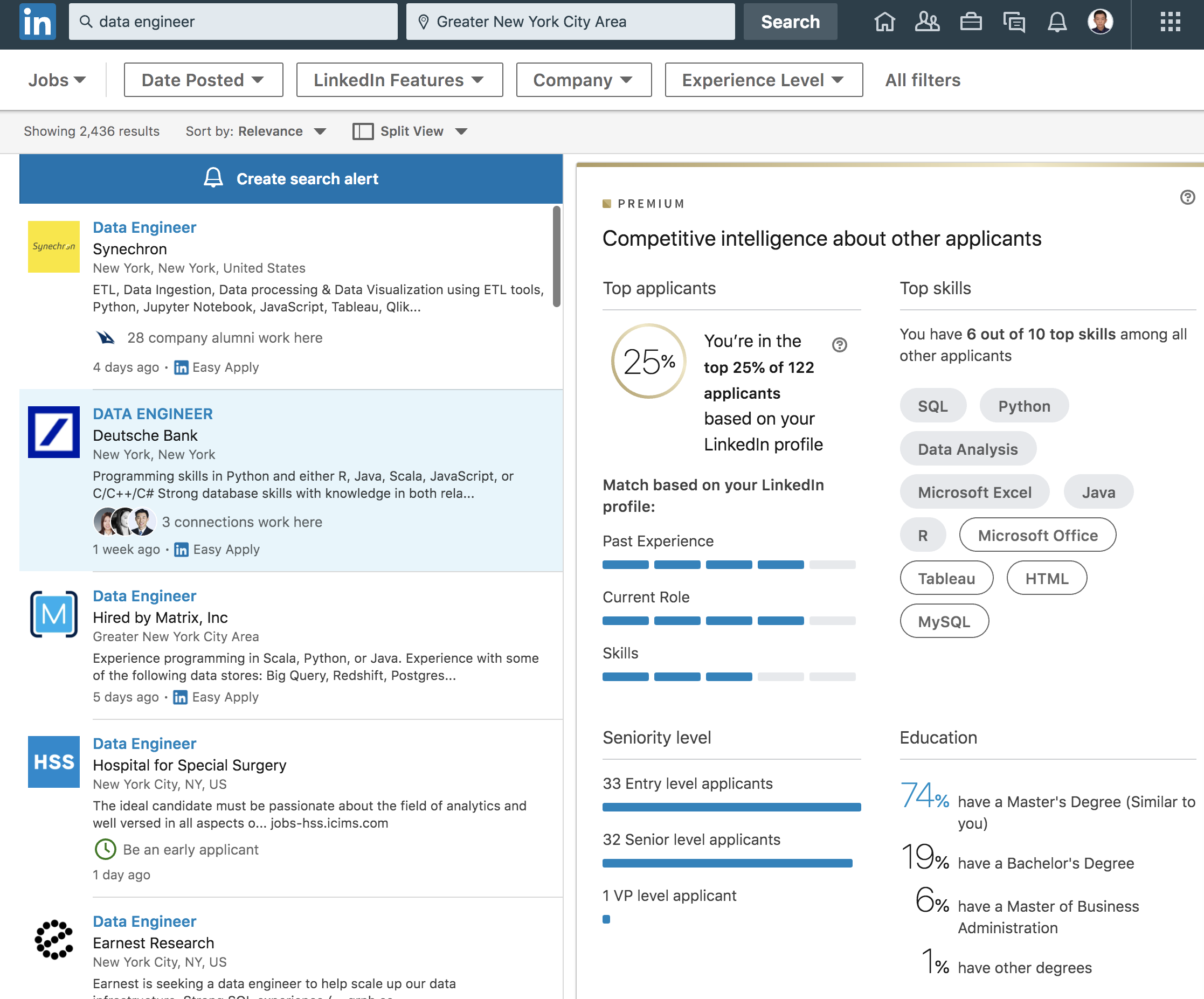
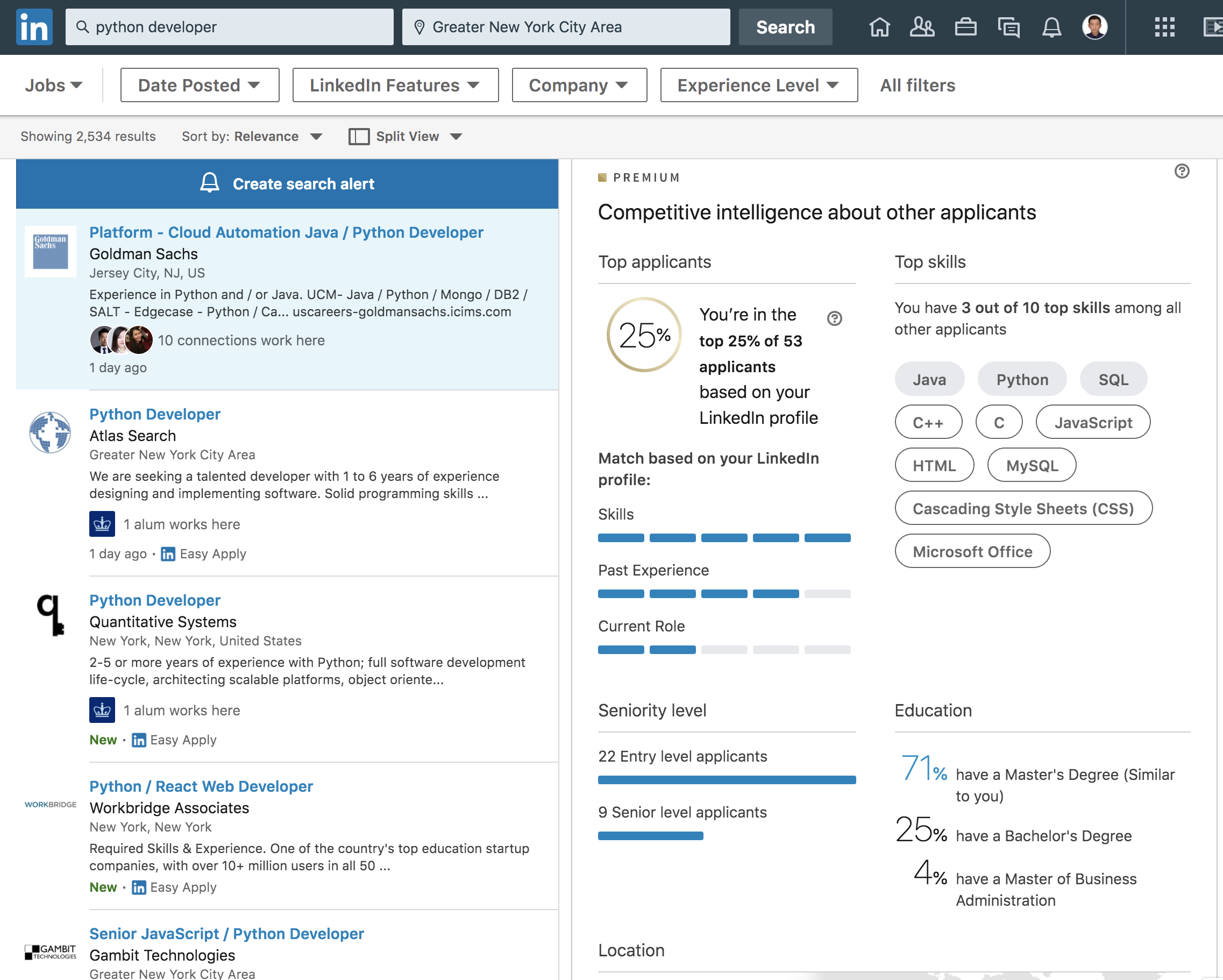
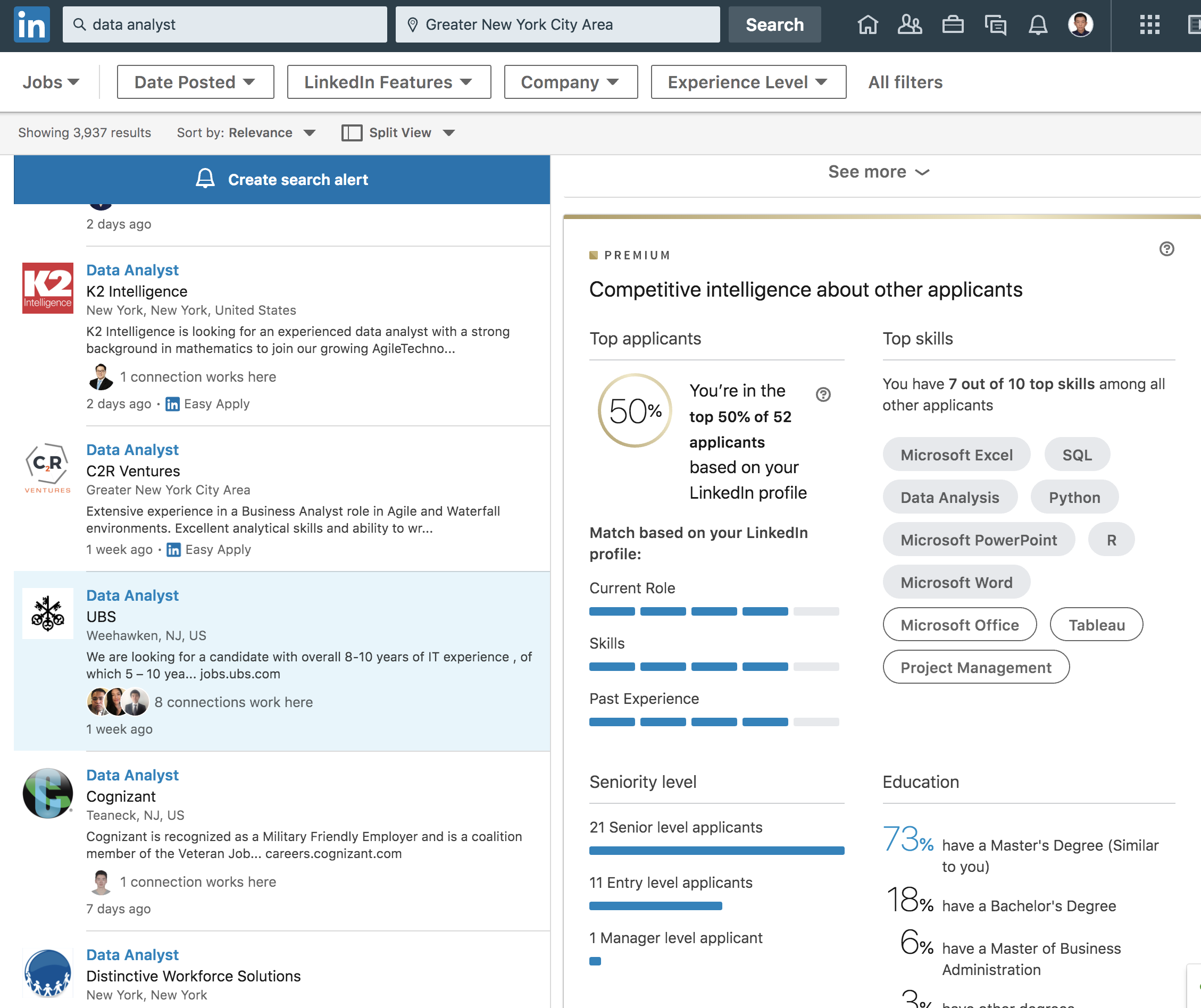
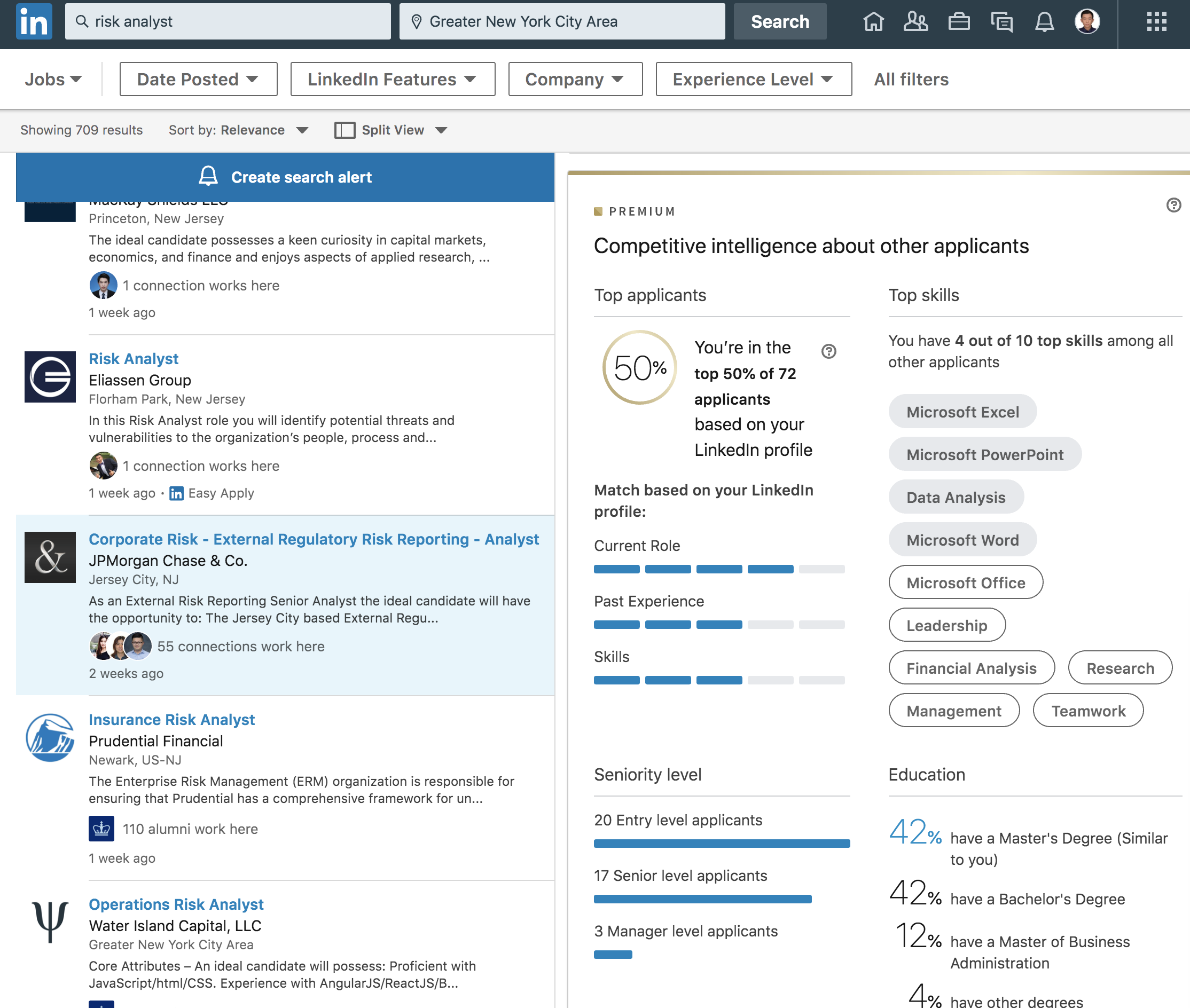
也就是说如果我投摩根大通的Risk岗八成是要凉的,可能连面试都拿不到。
简历的匹配度直接决定是否值得给你发面试!
简历小课堂3: Job Description关键词解构 (Reverse Engineer)
我想大部分人关心的是怎么样做出一个高匹配度的简历,能够确保你的简历在简历池当中脱颖而出。
我的方法是对各大网站比如Linkedin, Indeed和公司官网上你想要投的岗位的Job Description做一个Reverse Engineer.
我选出了最具有代表力的50家公司的Data Scientist岗,把所有Job Description提取出来放到Word文档里,逐字逐句解析, 分析出高频词汇和惯用语法,然后再对比我自己的简历,把所有高频词汇加进去,语法改成惯用语法,然后查缺补漏,什么技能不会补什么, 像什么Hadoop, Spark, MapReduce这些鬼东西我都是毕业后自己查缺补漏学的。

举一个例子:摩根大通的Data Scientist岗
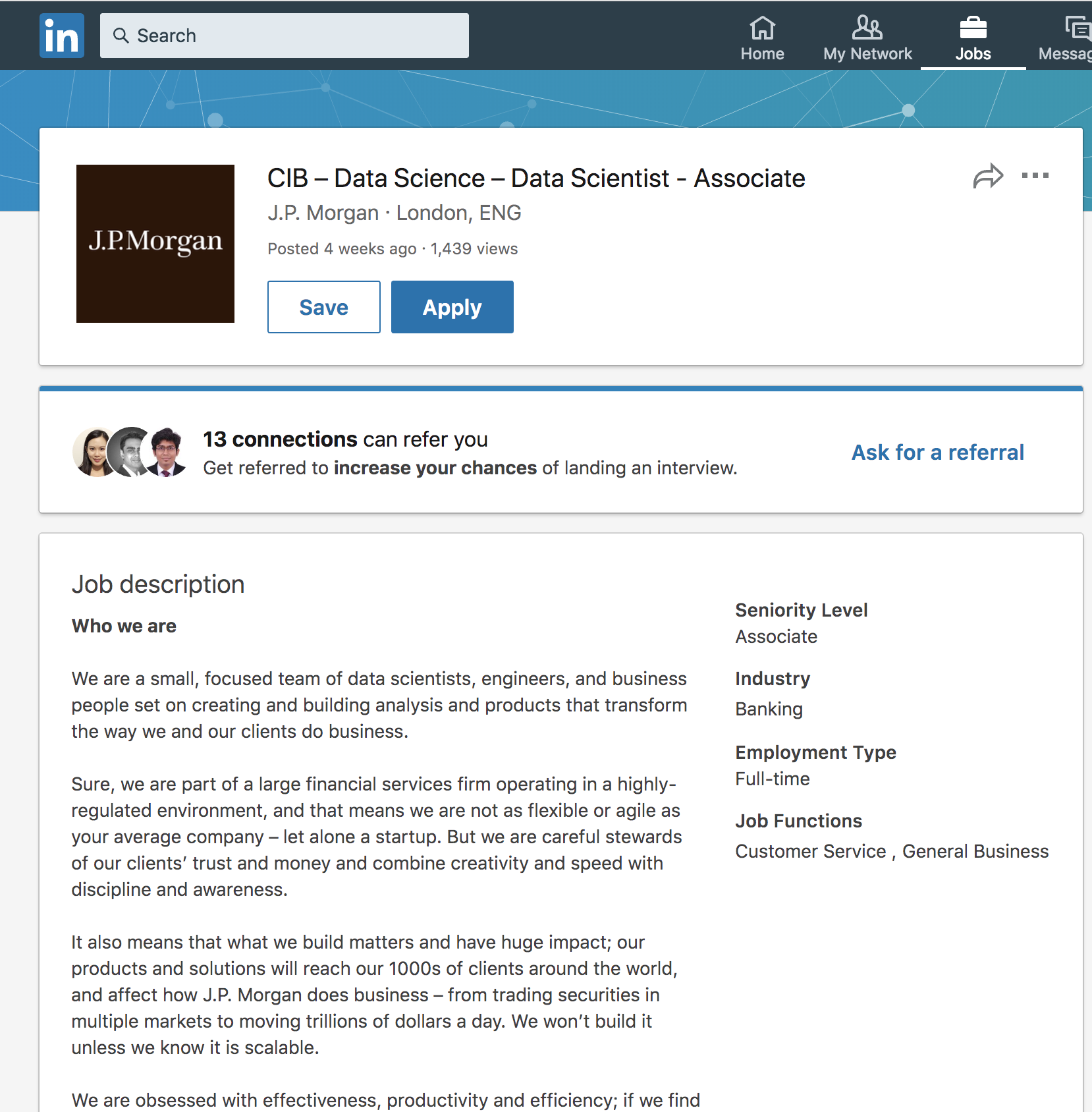


以摩根大通的Data Scientist岗为例提取出关键词,你完全就可以套用他的句式到自己简历,
比如:
- Researched, designed, implemented, and evaluated machine learning approaches and models including Linear Regression, Ridge, Lasso, Random Forest, GBM
- Performed data processing, data mining, text mining and information retrieval utilizing Python packages (numpy, pandas, NLTK, beautiful soup)
一句话总结:我的简历都是根据Job Description做的所以匹配度非常高,4份简历Data Scientist, Quant Research, Data Analyst, Data Engineer全部都拿到了面试。
简历小课堂Summary: 数据科学思维
其实做一份简历说白了就是一个NLP project,training data越相关越好,提取出高频关键词和常用句式,跟你自己的经历搭配组合,就能够写出一份好的简历。
用我们Data Scientist的术语来说就是:我做了一个Model (简历),用了一些Training Data (50家公司的Job Description), 在Test Data上的Performance准确率高达90% (拿一个新的DS的Job Description去匹配我的简历,排名是Top 10%), 而我用的Algorithm就是简单的Exploratory Data Analysis (高频词汇分析)